Introduction
In the previous article/analysis on defining archetypes we introduced the basic theory of Cluster Analysis (CA) and applied to a simple toy-example of Legends of Runeterra (LoR) decks.
We introduced the general theory along side a few widely-used algorithms and some of the “newer” ones like Density-Based Spatial Clustering of Applications with Noise (DBSCAN) and Affinity Propagation Clustering (APcluster).
The example was tailored to give a general idea about the methods, some of their strong point and also potential weaknesses with this specific context of analysing LoR decks.
As the previous analysis was mostly based around the basic approach to the methods and a well defined example it can’t translate directly to a generalized use with the commonly analysed data like the weekly reports.
For now, we want to continue to use the Cluster Analysis but this times applied to a set of data on a scale more similar to a real-case-study. To do this we first need to solve a couple of issues related to the scale of the algorithms at hand.
An Engineering Problem
What are the main issue when switching to data from a real-case study? Mostly the impact of the amount of decks to use with the resulting computational load. Also the dirtiness of the data resulting from not having a clean dataset, but that is to be expected.
Distance matrices and consequently all algorithm derived by them have a quadratic growth \(O(n^2)\) so scalability is a problem, even more so as this project to “define archetypes” is not meant to be purely theoretical. The aim of this project is to also apply it to the collected data and provide the results, be it in the reports or any other content so time has to be considered.
Yet, creating distance matrices at high dimension is not feasible even assuming the analysis is self contained and we have an infinite amount of time to compute the distances. Time is not the only factor, Space is too and probably it is even more important to find a way to solve it. One may not be used to these context so let us give some numbers of the problem at hand.
At the moment of the writing of this article our Deck’s dataset is made of about 1M decks 1. The dataset contains only 40-cards decks which has been played in Constructed or PvP modes.
Realistically, we would never try to works with all of them at the same time, at least not when using a cluster analysis (CA). A more appropriate time-frame can be a single competitive Season and restrict ourselves only to the decks played around that time.
To give a reference of a ‘real-case’ number, the Between Worlds (S10) Season which lasted from patch 2.18 to 2.20 featured at Master rank ~42000 unique decks.
As we are not ready yet to just simply apply any methods to any kind of decks data we are going to create a dataset so that is has a similar scale of the S10-MasterRank (42000) decks.
For this article we planned to create an example made of 44000 decks. The creation criteria will be explained in another moment. Its size is clearly to have an order of magnitude similar to the S10-MasterRank numbers. Se say planned as the actual analysis of the dataset is being delayed because of issues we just introduced.
Let us now give some more numbers of the problem at hand, let’s talk about the memory allocation of the distance matrix:
If we used only a fraction of the chosen decks, just 1100, then we would have a \(1100 \times 1100\) distance matrix that requires: 4.7 Mb
If we increased the choice to 5500 decks, the resulting 5500x5500 distance matrix would occupy: 115.7 Mb.
Quite the increase but consistent to the fact that the second matrix is 25 times the smaller one and we can see the issue with the quadratic growth that comes with the matrix.
- By using all the 44k decks we can’t even try to recreate the distance matrix, it would require a very good machine and we can infer that just the distance matrix size with its \(44000^2\) elements would be of around 7424 Mb. We wouldn’t be able to allocate enough memory to save it, let alone work with it.
Overall, while it would be nice to work with any available data (assuming it’s meaningful) one can’t ignore the time/cost that comes from each choice and so we need to search for a way to circumnavigate the issue. While we don’t have the perfect solution, we are going to propose a way to approach the problem making it a bit more feasible.
Discussion
Needles in the Shuriman (vast) Desert
Let us assume that we are able to solve the computation and allocation of the distance matrix; this would solve the engineering-side of the problem it would most likely be an incredible ‘a waste’ of resources.
To explain this we are going to show the resulting heatmaps of a couple of subsets of the example dataset. One with a subset of 1100 decks and another one with 5500 decks. In both cases the subset decks are chosen not completely at random.
The resulting heatamap with 1100 decks is:
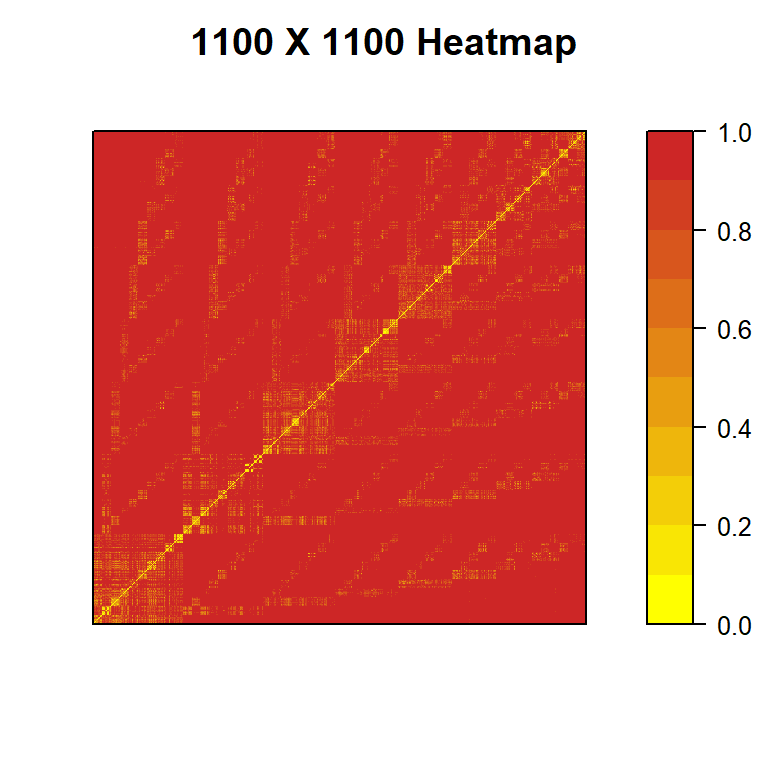
Figure 1: heatmap of a 1100 x 1100 distance matrix of LoR decks chosen not completely at random
The resulting heatamap with 5500 decks is:
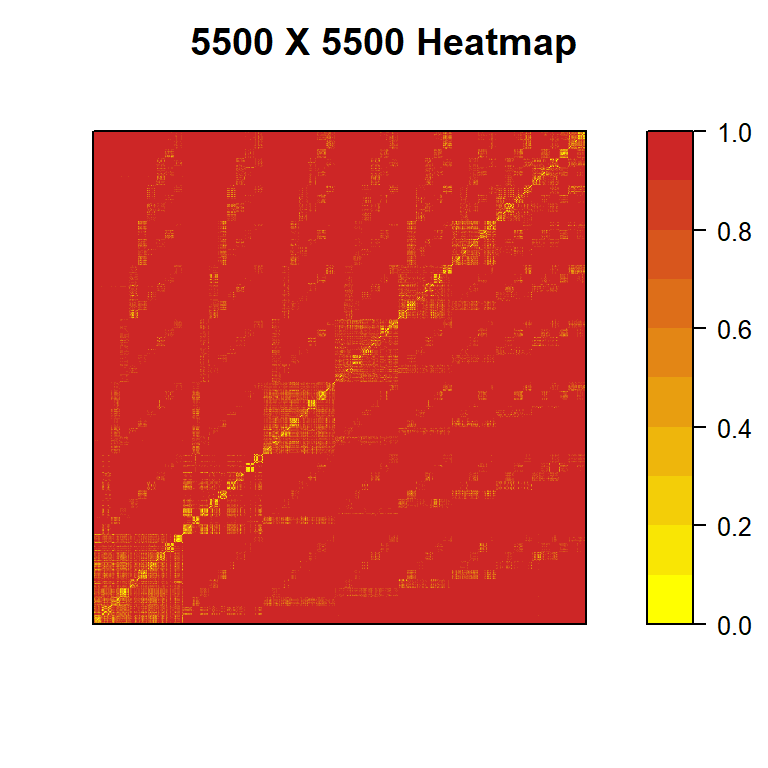
Figure 2: heatmap of a 5500 x 5500 distance matrix of LoR decks chosen not completely at random
As we can see in Fig:1 and Fig:2 there are clear indication of the presence of several small clusters (the yellow areas) but in the majority, the vast majority of the matrix, the distance is at its max (1) and the similarity is at its min (0) 2.
While we need to account for the decks that compose the example, in a typical real-case the results would be similar in most cases.
There is a structural reason behind this and that’s a result of the limitation imposed by the deck building process which doesn’t allow the use of cards from more than two different regions (not counting Dual Region cards). This makes almost all pair of decks decks with no common region having a similarity that has to be zero (again, dual region cards aside).
Our proposed solution is to use this information and start simplify the problem to a series of smaller one cases.
Because of the limitation in deck building we know that the similarity of decks with no common faction has to be zero. A Noxus-PnZ deck has to have a similarity equal to zero with a ShadowIsles-Shurima deck and if we order the deck by faction it means that the distance matrix is made of several \(0_{n \times n}\) sub null-matrix.
To be more precise, there are sadly exception to this property: when we deal with dual region cards we can have non overlapping factions but still common cards 3.
Example: a BandleCity/Noxus (BC/NX) deck and a Demacia/Ionia (DE/IO) deck both sharing “Poppy” as a card. Both their regions are different but the similarity if not null is we are going to use the original card code of a card.
For now everything we will do will ignore the dual-region issue and leave it for for future works.
The Lazy Approach
Let’s assume we don’t have the problem of the Dual-Region cards and all the 10 regions, what do we know about the structure of the similarity matrix?
We know that there are 55 unique combination of region and so when comparing two decks it can fall into one of \(55^2\) possible confrontation. Of course as we know that the Matrix is symmetrical it’s reduced to just 1540 cases.
Of these 1540 cases, as we already explained, most of them are made of null-matrix. But how many exactly?
As we mentioned only when there is at least a common region the similarity can be different from zero. This makes it so the number of sub-matrix to consider follows the following formula:
\[ \sum_i^n((i-1)^2+\frac{i(i+1)}{2}) \]
The following table shows the percentage of sub-matrix that can be not-null depending on the number of existing regions:
| Sparsity of Similarity Matrix | |
|---|---|
| Percent of sub-matrix that share a common region by number of existing regions. |
|
| region | coverage |
| 1 | 100.00% |
| 2 | 83.33% |
| 3 | 71.43% |
| 4 | 61.82% |
| 5 | 54.17% |
| 6 | 48.05% |
| 7 | 43.10% |
| 8 | 39.04% |
| 9 | 35.65% |
| 10 | 32.79% |
Tab. 1: Percent of sub-matrix that share a common region by amount of by number of existing regions.
From Tab. 1 we can see that in the current setting with n=10 existing regions, of the 1540 cases only the 32.8% of pairing of combination of regions is actually meaningful with a similarity that can different from zero.
But this is not over as again only a small subset of this 32.8% is actually relevant.
Of the region comparisons all sub-matrix in the diagonal (55) are of course necessary/relevant (so all NX/PZ vs all NX/PZ), what remains are the cases with only one shared region.
When we compare decks with a single shared region not all comparison are meaningful and what follows is a simplification which works for most cases.
If pairs of decks shares only one regions, for the similarity not to be zero that very same region needs to contains all the common cards. Usually it means that the shared cards are key component to a strategy and unless they are mainly staples they would probably identify an archetype. In the most extreme case the shared region presence may be overwhelming compared to the second one which is used only for the second region unique strength offered by some cards. Like the Rally effects from Demacia.
In other words, when comparing pair of decks with a single shared region, since we aim to look for clusters, the decks that matters are the “bridge” among the regions with a main region that mostly identify the deck.
As easy example is the Mistwraith decks that we also used in the previous article 4.
Normally Mistwraith decks are made mostly of Shadow Isles cards while the remaining cards are often from a region of choice that synergies with the rest of the deck but are not essential / key-cards. This cards act are the bridge between regions.
Is the deck using as the only not-SI cards 3 copies of Pale Cascade? Then it’s a SI/MT deck
Is the deck using as the only not-SI cards any copies of Raz Bloodmane? Then it’s a SI/SH deck and SI/MT and SI/SH are connected
Is the deck using as the only not-SI cards 3 copies of Iterative Improvement? Then it’s a SI/PZ deck and we connected SH,MT and PZ by SI.
And so on with all the non-SI regions.
Of course as mentioned this is more an approximation as one could that a Mistwraith deck with just 20 SI cards and a lot of duplication cards, the deck could still be defined as Mistwraith decks; here we are going to assume that such identification is an over-simplification and it’s more likely it would be better to define that ‘20 SI cards Mistwraith deck’ as a sub-archetype of Mistwraith Allegiance. While the main archetype and the sub-archetype would have a similar strategy, we believe it would have a play-pattern that differs enough from the ‘main Mistwraith Allegiance’ as the amount of cards from the second region would have a greater impact.
What we propose is to use only the ~mono-region decks, add them to the the true-mono region sub-matrix and ignore most of the remaining cases of comparisons of decks with only one shared region.
The result would for example having all mono-region Noxus decks with all ~mono-region NX/BW, NX/DE, NX/FR,… and reduce all the off-diagonal sub-matrix to n=10 cases, one for each region.
In a TL:DR we end up reducing our initial problem with 1540 sub-matrix to one with 45 sub-matrix containing all dual region combinations and 10 sub-matrix which contains all the MonoRegion decks AND all the ~mono region decks. The almost mono-region decks will end up being used twice overall but it’s a small increase compared to the smaller coputational load overall.
Cross-Region Comparisons
When confronting decks with only a shared region we explained how we consider more appropriate to only use bridge decks and considering all the other cases as with null similarity. This open for question: how do we define these bridge decks? Intuitively we described how they mainly relates to cases where a region has an overwhelming playrate compared to the second one, or to put it on another term they are almost mono-region decks.
If so, at which point a deck can be considered almost mono-region? What benchmark and rules should we use?
This is tricky but our idea is to use both an hard defined benchmark and the presence of Allegiance cards.
The choice to include the use of Allegiance cards is meant to be a clear and easy to understand rule that at the same times allows for a more “fuzzy separation” of ~Mono decks with the not-mono decks. The allegiance rule should be able to include some decks that may still point toward a certain strategy that is connected to the region identity while not investing as much cards from that region.
As such, one question may arise: doesn’t the presence of Allegiance cards requires already a massive amount of cards in a deck from the same region of the allegiance card? It does. But it’s not an hard requirement. Also one shouldn’t underestimate the wild deckbuilding that can be found even at high level ranks, even if few, it’s possible to find all kind of wild decks. We are going to now provide a couple of characteristics of the presence of Allegiance cards in the “Between Worlds Master rank” decks.
Tab. 2: Frequency table of all combination of card and copies of Allegiance cards played in the S10 at Master rank.
First and foremost with Tab. 2 we can see that simply assuming Allegiance cards identify the main region of a deck is not completely fail-proof as they may exist decks that use Allegiance cards from both regions of a deck. Of course they are extreme cases, they are exception to the rule but as they exist they needs to be accounted for. For now we will simply remove these cases if encountered.
For the amount of cards from the same region we propose to use all decks with no less than 32 cards from the same region (80%+ cards from the same region). This choice is mostly a guided personal choice than a data-driven one even if we will be able to see that data sort of confirm the validity of choice.
The reason behind the choice is a such when creating an Allegiance deck that wants to use an Allegiance card deck one can push a second risk with the risk at the main region not being as consistent as it could:
Using 3 cards from the second region minimize the risk of failing Allegiance while maximizing the use a very strong card from the second region.
Most players would agree that without card draw control, more than 10 cards from the second region (25%+) is pushing luck.
Of all the other cases in the middle having 8 cards from the second region (20% of the total) is probably the most one may push with the risk-benefit.
The following table shows the relationship of Decks with Allegiance cards with the amount of cards from the same region of the Allegiance card.
| Cumulative Frequencies of Allegiance Decks | ||
|---|---|---|
| Percentages by decreasing amount of cards from the same region of the Allegiance card. | ||
| same region cards | n | cumulative frequency |
| 40 | 490 | 14.57% |
| 39 | 35 | 15.61% |
| 38 | 157 | 20.28% |
| 37 | 840 | 45.26% |
| 36 | 790 | 68.75% |
| 35 | 438 | 81.77% |
| 34 | 303 | 90.78% |
| 33 | 109 | 94.02% |
| 32 | 62 | 95.87% |
| 31 | 31 | 96.79% |
| 30 | 16 | 97.26% |
| 29 | 10 | 97.56% |
| 28 | 14 | 97.98% |
| 27 | 11 | 98.31% |
| 26 | 17 | 98.81% |
| 25 | 8 | 99.05% |
| 24 | 2 | 99.11% |
| 23 | 6 | 99.29% |
| 22 | 5 | 99.44% |
| 21 | 5 | 99.58% |
| 20 | 4 | 99.70% |
| 19 | 1 | 99.73% |
| 18 | 2 | 99.79% |
| 17 | 1 | 99.82% |
| 16 | 1 | 99.85% |
| 15 | 2 | 99.91% |
| 12 | 2 | 99.97% |
| 9 | 1 | 100.00% |
| Values from the example dataset created for this article. The dataset is made of 800 random decks for each of the 55 combinations of regions among the decks collected over time. | ||
Tab. 3: Cumulative Frequencies of Allegiance decks by decreasing amount of cards from the same region of the Allegiance card.
From Tab. 3 we can see that in this example 32 cards is the benchmark which allows to include 95% of the Allegiance decks and we are satisfied by this.
The most surprising result is the presence of decks that have a very few amount of cards from the same region of the Allegiance card like the following example
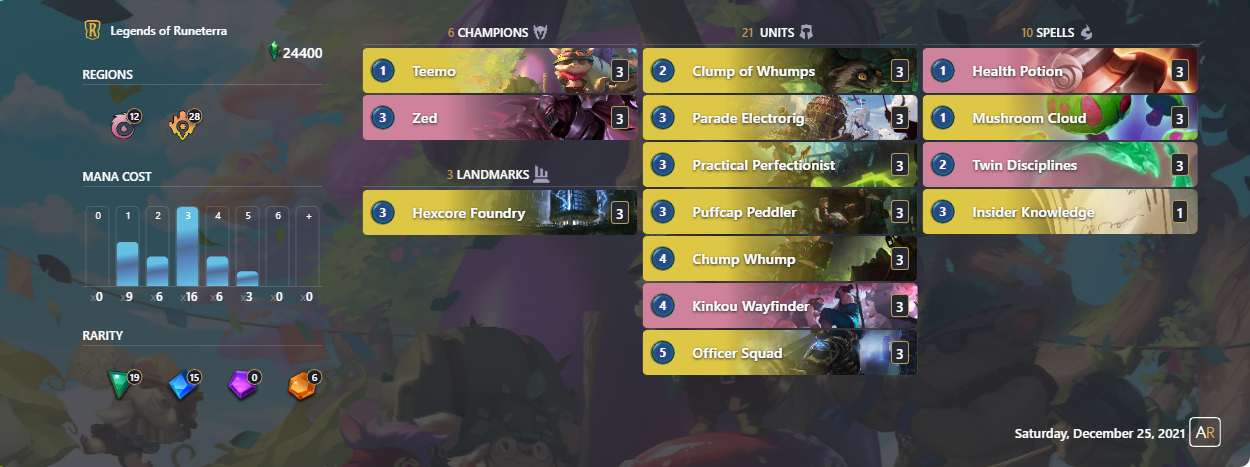
The above deck is an example of those decks. While strange we can still see that it’s supposed to be a different take from the Teemo-Ionia decks that are usually played. Would this case be more appropriate to be considered noise for that archetype? Maybe but at the same time we can also assume it’s an archetype of its own. Overall this is problem related to what defines an archetype. This topic will be explored in the next article as we are trying to apply this approach to the example dataset, or to be more correct, to two of the 55 possible subsets of the example dataset, one for a MonoRegion case and one for a generic dual-region case.
Conclusion
Overall this was a very simple article of the subject but that is key to the archetype problem. Again and again I usually start with an idea I have in mind for what should follow an article I just released and each time while in the process of doing it I find myself having to deal with many different issue that needs to be solved before going forward. In this case I wanted to simply apply the cluster algorithms from the second article to the example dataset created here and had to deal with the resources problem (well that one was expected actually) and having to define the rules which allows for the overall data to be divided.
The proposed method still has a \(O(n^2)\) computational complexity but it also has at least one order of magnitude less than the starting problem by switching the focus to each possible region combination. This should solve the computational-load for the time being but now the true challenge begins, the dirtiness of the data still remains.
The next article should try to deal with this dirtiness and the problem of defining what defines an archetype which is related to the Theseus Ship dilemma. When does an archetype stops being the same archetype after changing one card at a time? Here I won’t promise I will find a personal answer to the problem but again at least something that will allows me to provide some results for the two sub-examples I’m planning to tackle. Will it actually be what the next article will accomplish? Hard to say, but at least that’s the new visible goal.
Constructed, SeasonalTournamentLobby, Bo3ChallengeLobby, StandardGauntletLobby, LastCallQualifierGauntletLobby↩︎
[0,1] being the domain of the cosine-similarity.↩︎
BandleCity Ruined more than the Ruination↩︎
At the moment of the writing the Ionia-Allegiance decks provides an even more easier example as similar to Mistwraith decks they are often made of only Ionia cards and differ mostly by the choice of the second region↩︎